■ データを貯めたら使い道を考えよう
wgetで気に入ったページをコピーしたら素早く取り出せる仕組みを考えましょう。そうですGoogleとかと同じように全文検索システムの構築です。これでローカルサーバーも検索サーバーに早変わり、なんて実用的なサーバーなんでしょう。
[1]Namazuのインストール
いつものようにパッケージからインストールします。画像省略。
様々な必要ソフトもインストールされます。本当、パッケージって便利だわ。
[2]httpd.confの設定。
CGIを使えるようにする。コメントをはずすだけ。
AddHandler cgi-script .cgi
#
[3]namazuの設定。
CGIプログラムと設定ファイルをコピー
clio# cp /usr/local/libexec/namazu.cgi /usr/local/www/cgi-bin
clio# cp /usr/local/etc/namazu/namazurc-sample /usr/local/www/cgi-bin/.namazurc
.namazurcを編集
Index
/usr/local/var/namazu/index
Template /usr/local/var/namazu/index
Replace /usr/local/www/home-user/yuzo/
http://www.home.or.jp/~yuzo/
Lang ja
インデックスファイルとCGIで出力されるHTMLの設定ファイルの格納ディレクトリですがデフォルトで良いと思うので、それにあわせてディレクトリ作成。
clio# mkdir /usr/local/var/namazu
clio# mkdir /usr/local/var/namazu/index
clio# chmod 777 /usr/local/var/namazu/index
インデックスデータ作成(LANGを設定しないと出来上がったインデックスファイルの漢字コードが揃わないため表示が化けることがあります。絶対設定すべし!)
clio# setenv LANG ja_JP.EUC
clio# mknmz -O /usr/local/var/namazu/index /usr/local/www/home-user/yuzo/wget
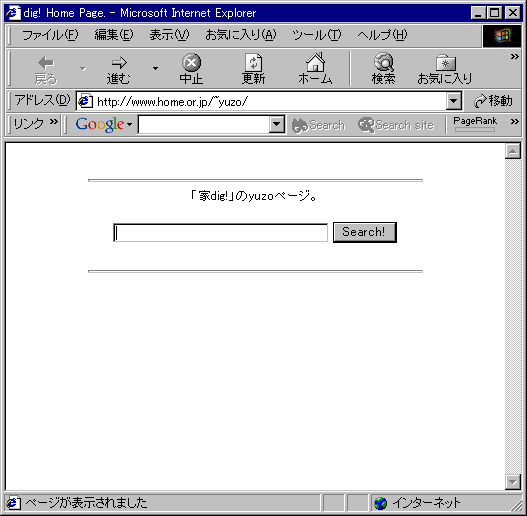
HTML文書にCGI呼び出しを記述する。たとえばこんな文書を作って。赤文字部分がCGI呼び出し部分。
<!doctype html public "-//w3c//dtd html 4.0 transitional//en">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html;
charset=Shift_JIS">
<meta name="GENERATOR" content="Mozilla/4.7 [ja]
(WinNT; I) [Netscape]">
<meta name="Author" content="yuzo">
<title>dig! Home Page.</title>
</head>
<body>
<br>
<hr size="3" width="70%">
<center>「家dig!」のyuzoページ。</center>
<center>
<FORM METHOD="get" ACTION="/cgi-bin/namazu.cgi">
<INPUT TYPE="text" NAME="query" size="40">
<INPUT TYPE="submit" NAME="submit" VALUE="Search!">
</FORM>
</center>
<hr size="3" width="70%">
<br>
</body>
</html>
こんな画面をつくります。
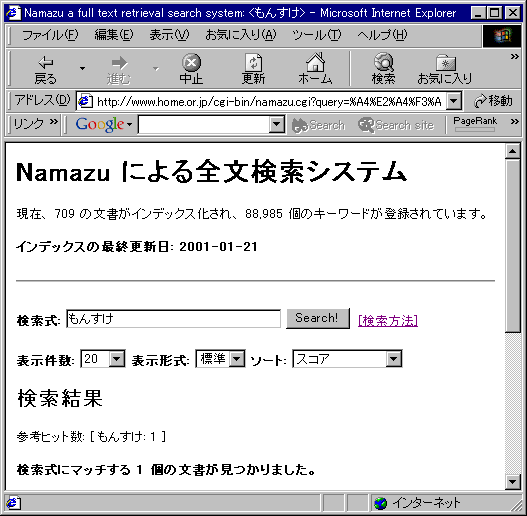
検索するとこんな感じ。
|